Computers deal with numbers, not with characters. When you save a text file, each character is mapped to a number, and the numbers are stored on disk. When you open a text file, the numbers are read and mapped back to characters. When saving a file in one application, and opening that file in another application, both applications need to use the same character mappings.
Traditional character mappings or code pages use only 8 bits per character. This means that only 256 distinct characters can be represented in any text file. As a result, different character mappings are used for different languages and scripts. Since different computer manufacturers had different ideas about how to create character mappings, there’s a wide variety of legacy character mappings. EditPad supports a wide range of these.
In addition to conversion problems, the main problem with using traditional character mappings is that it is impossible to create text files written in multiple languages using multiple scripts. You can’t mix Chinese, Russian and French in a text file, unless you use Unicode. Unicode is a standard that aims to encompass all traditional character mappings, and all scripts used by current and historical human languages.
If you’ve received a text file from another person, or opened a file created on another computer, it may not immediately be readable in EditPad. Two things need to be set right. You need to use a font that can display the characters in your file. If you see hollow rectangles instead of characters or if characters are missing entirely then you are not using the correct font. You also need to use the correct encoding for the file so that EditPad knows which characters are represented by the bytes in the file. If you see incorrect characters (Chinese gibberish instead of English, for example) then you need to change the encoding.
While all fonts contain English characters, far fewer fonts contain Chinese, Thai, or Arabic characters. In EditPad, select Options|Font in the menu to select a font that supports the language your file is written in. Windows includes many different fonts tailored to specific languages or scripts.
If you use multiple scripts in a single file, then you probably won’t have a single font that can (nicely) display all of those scripts. Fortunately, EditPad can use any number of fonts at the same time. It can automatically use each font only for those scripts that each font supports. Select Options|Text Layout in the menu. Set “text layout and direction” to “complex script”. Select a main font and any number of fallback fonts. If the main font doesn’t support a certain script, EditPad displays that script using the first fallback font that does support that script.
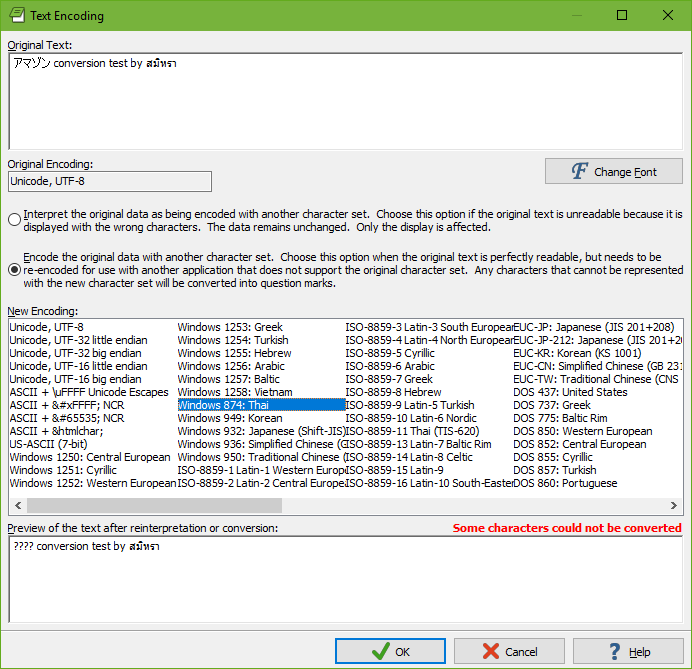
If you see incorrect characters, select Text Encoding in the Convert menu to change the encoding EditPad uses for that file.
At the top of the screen, you will see part of the file as EditPad interprets it now, along with the encoding used. Make sure “interpret the original data as being encoded with another character set” is marked. Then try selecting a new encoding. The result appears immediately in the preview at the bottom of the screen. Keep trying different encodings until you find one that produces a readable file.
If the file was created on a computer running Windows, try the Windows encodings first. All Windows computers use one of the Windows encodings as the default. UTF-8 and UTF-16 little endian are also likely, as Unicode is becoming popular among modern Windows applications.
If the file was created on a computer running a UNIX variant such as Linux, try the ISO-8859 and EUC encodings. UTF-8 and UTF-16 little endian are also likely.
If the file was created on a modern Mac running OS X, it probably uses UTF-8. If it was created on an older Mac, try the Mac encodings.
If the file was created by an old DOS application, try one the DOS character sets. The DOS character sets were used by Microsoft’s MS-DOS and DOS versions from other companies. If you know that the file is supposed to contain “line drawing symbols”, the DOS character sets are also very likely. The DOS character sets are the only ones that contain line drawing symbols. DOS applications used characters that look like lines, bevels and corners to draw pseudo-graphical interfaces on character-based screens. DOS predates Unicode, so the Unicode formats are unlikely, even if they contain line drawing symbols.
If the file is written in Russian or Ukrainian, the KOI8-R and KOI8-U encodings are very likely candidates, even for files created on Windows or UNIX systems. Particularly ISO-8859-5 has never reached the popularity of KOI8.
If the file was created on an old mainframe or an IBM AS/400 (renamed iSeries) system, try the EBCDIC encodings. EBCDIC was the de facto standard in the days computers used punch cards. If EBCDIC doesn’t produce a readable file, try the DOS character sets, which were used by IBM’s PC-DOS.
There are two ways in which a text editor can keep files in memory while editing them. Some editors use Unicode internally. On Windows that is typically UTF-16 LE. When you open a file that uses any other encoding, it is converted into UTF-16 LE in memory. When you save the file, it is converted back into the other encoding. The benefit is that the developers of such editors have only one encoding to deal with for all editing functions. The downside is that the conversion takes extra time and extra memory. Such editors usually don’t perform well with very large files. If a file is loaded with the wrong encoding, it has to be reloaded with the correct one. If you don’t notice the wrong encoding is being used, or if it contains bytes that are invalid for the encoding that the file actually uses, data loss may occur. There’s no way to preserve invalid byte sequences when converting to UTF-16.
When EditPad loads a file, it loads its actual bytes into memory. In EditPad Pro you can even see those bytes by switching to hexadecimal mode. That is what the term “original data” in the choices in the Convert|Text Encoding window refers to. Because EditPad keeps the file’s original bytes in memory, it can instantly change how it interprets those bytes. Simply use the “interpret” option in the Text Encoding window and select another encoding. This option does not change the contents of the file at all, nor is there any need to reload the file. It only changes how EditPad translates the bytes into characters.
While you edit a file, EditPad converts those bytes into characters on-the-fly for display. When you type in or paste in new text, EditPad immediately converts the characters you enter into the appropriate bytes for the file’s encoding. That means that if your file doesn’t use Unicode, you can only enter or paste characters that are supported by the file’s encoding. EditPad’s Character Map can show you all those characters.
If you paste characters that are not supported by the file’s encoding, EditPad has no way to convert those characters into bytes to store them into the file. Such characters are lost. They are permanently changed into question marks to indicate the actual characters you tried to paste could not be represented. In order to paste the actual characters, first use Edit|Undo to remove the question marks. Then use Convert|Text Encoding with the “encode original data with another character set” option. Select a Unicode transformation or any encoding that supports the characters you want to paste, as well as those already present in the file. EditPad then changes the bytes in the file to represent the same characters in the new encoding. Now you can paste your text again and get the actual characters. Note that you have to undo pasting the question marks. Changing the encoding does not magically restore the characters. Since EditPad Pro uses the file’s actual encoding for in-memory storage rather than Unicode, newly entered or pasted characters that cannot be represented cannot be stored.
To make sure other people can read files you’ve written in EditPad, simply save it in an encoding that the other person can read. If he or she also uses Windows, you don’t need to do anything. EditPad’s default text encoding settings save the file in your computer’s default Windows code page.
If the file is written in English, you also have little to worry about. English text is encoded the same way in UTF-8, all Windows code pages, all ISO-8859 code pages, all DOS code pages, all Mac code pages, and also KOI8.
If your document uses non-English characters, and you’re not sure which encodings the other person can read, the UTF-8 encoding is a safe bet. UTF-8 files usually start with a byte order marker to identify them. EditPad and many other applications running on Windows, Linux and Mac OS X detect the byte order marker, and automatically interpret the file as UTF-8. Since UTF-8 is a Unicode transformation, it supports all modern human languages. All characters present in any of the non-Unicode code pages supported by EditPad are also present in the Unicode mapping.
To change a file’s encoding, select Text Encoding in the Convert menu. Mark the “encode original data with another character set“ option and select the encoding you want to convert the file into. If you get a bold red warning that some characters could not be converted, this means that the encoding you are trying to convert the file into cannot represent some characters you’ve used in the file. Those characters will be replaced by question marks if you proceed with the conversion. The Unicode encodings are the only ones that can represent all characters from all human languages. The others are typically limited to English plus one language (e.g. Chinese) or one group of languages (e.g. Western European languages).