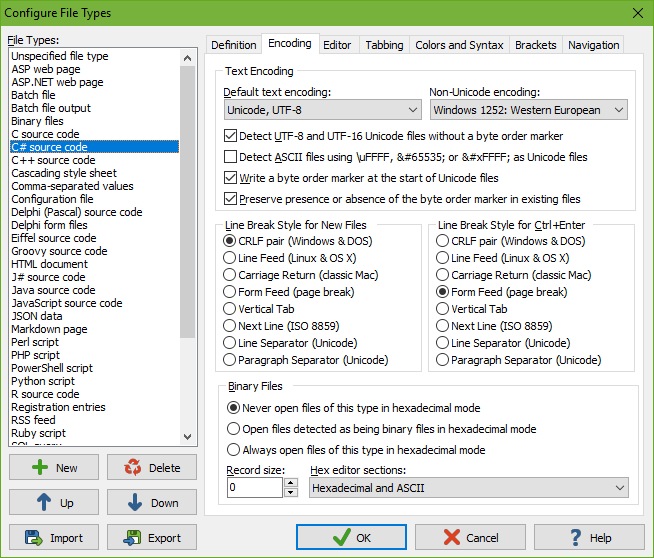
On the Encoding tab in the file type configuration, you can indicate how EditPad should encode and decode files of a particular type.
Computers deal with numbers, not with characters. When you save a text file, each character is mapped to a number, and the numbers are stored on disk. When you open a text file, the numbers are read and mapped back to characters. When saving a file in one application, and opening that file in another application, both applications need to use the same character mappings.
Traditional character mappings or code pages use only 8 bits per character. This means that only 256 distinct characters can be represented in any text file. As a result, different character mappings are used for different languages and scripts. Since different computer manufacturers had different ideas about how to create character mappings, there’s a wide variety of legacy character mappings. EditPad supports a wide range of these.
In addition to conversion problems, the main problem with using traditional character mappings is that it is impossible to create text files written in multiple languages using multiple scripts. You can’t mix Chinese, Russian, and French in a text file, unless you use Unicode. Unicode is a standard that aims to encompass all traditional character mappings, and all scripts used by current and historical human languages.
If you only edit files created on your own Windows computer, or on other Windows computers using the same regional settings, there’s not much to configure. Simply leave the “default text encoding” set to the default Windows code page, e.g. Windows 1252 for English and other Western European languages. If you edit files created on Windows computers with different regional settings, you may need to select a different Windows code page. You can either change the default for the file type, or use Convert|Text Encoding for a one-time change.
On the Windows platform, Unicode files should start with a byte order marker. It is often abbreviated as BOM. It is also known as a Unicode signature. The byte order marker is a special code that indicates the Unicode encoding (UTF-8, UTF-16 or UTF-32) used by the file. EditPad always detects the byte order marker and always treats the file with the corresponding Unicode encoding.
Unfortunately, some applications cannot deal with files starting with a byte order marker. XML parsers are a notorious example. If an application that claims to support Unicode fails to read Unicode files saved by EditPad, try turning on the option not to write the byte order marker.
If you turn on the option “preserve presence or absence of the byte order marker in existing files”, then EditPad will keep the BOM in files that already have it, and never add it to Unicode files previously saved without a BOM. When preserving the BOM or its absence, the option “write a byte order marker at the start of Unicode files” is only used for files that you newly create with EditPad and for files that you convert from a non-Unicode encoding to Unicode. Non-Unicode files cannot have a BOM. So there is no presence or absence of the BOM to maintain if the file was not previously Unicode.
If you want EditPad to open Unicode files saved without a byte order marker, you’ll either need to set the default encoding for the file type to the proper Unicode encoding, or turn on the option to auto-detect UTF-8 and UTF-16 files without a byte order marker.
To auto-detect UTF-8 files, EditPad Pro checks if the file contains any bytes with the high order bit set (values 0x80 through 0xFF). If it does, and all the values define valid UTF-8 sequences, the file is treated as a UTF-8 file. The chances of a normal text document written in a Windows code page being incorrectly detected as UTF-8 are practically zero. Note that files containing only English text are indistinguishable from UTF-8 when encoded in any Windows, DOS or ISO-8859 code page. This is one of the design goals of UTF-8. These files contain no bytes with the high order bit set. EditPad Pro will use the file type’s default code page for such files. This makes no difference as long as you don’t add text using letters outside the English alphabet.
Reading a UTF-16 file as if it was encoded with a Windows code page will cause every other character in the file to appear as a NULL character. These will show up as squares or spaces in EditPad. EditPad can detect this situation in many cases and read the file as UTF-16. However, for files containing genuine NULL characters, you may need to turn off the option to detect UTF-8 and UTF-16 files without the byte order marker.
Some file formats consist of pure ASCII with non-ASCII characters represented by Unicode escapes in the form of \uFFFF or by numeric character references in the form of  or . EditPad Pro has ASCII + \uFFFF and ASCII + NCR text encodings that you can use to edit such files showing the actual Unicode characters in EditPad, but saving the Unicode escapes or numeric character references in the file. Turn on “Detect ASCII files using \uFFFF,  or  as Unicode files” to automatically use these encodings for files that consist of pure ASCII and that contain at least one of these Unicode escapes or numeric character references. By default, this option is only on for Java source code, because in Java there is no difference between a Unicode escape and the actual Unicode character. You can also turn it on for HTML or XML if you like to write your HTML and XML files in pure ASCII with character references.
If you set the default encoding to Unicode and you open a file without a BOM then EditPad uses the same auto-detection methods to verify that the default encoding is correct for the file. It verifies the default encoding even if you disabled the auto-detection methods. If the bytes in the file are not valid for the default encoding then EditPad uses the detection methods that you did enable to try the other Unicode encodings. If those fail too, then EditPad falls back on the “non-Unicode encoding” that you selected for the file type. This way selecting UTF-16 as your default encoding doesn’t cause files using a Windows code page to appear as Chinese gibberish. You can select the Windows code page as the non-Unicode encoding to fall back on.
If the presence or absence of a BOM is important to you then you should turn on the Unicode signature status bar indicator. It indicates whether the file has a BOM or not. You can click the indicator to add or remove the BOM if you selected to preserve its presence or absence for the active file’s file type.
If the differences in character mappings weren’t enough, different operating systems also use different characters to end lines. EditPad automatically and transparently handles all eight line break styles that Unicode text files may use. If you open a file, EditPad maintains that file’s line break style when you edit it. EditPad only changes the line break style if you use Convert|Line Break Style.
Unfortunately, many other applications are not as versatile as EditPad. Most applications expect a file to use the line break style of the host operating system. Many Windows applications display all text on one long line if a file uses UNIX line breaks. The Linux shell won’t properly recognize the shebang of Perl scripts saved in Windows format (causing CGI scripts to break “mysteriously”).
In such situations, you should set a default line break style for the affected file types. When you create a new file by selecting a file type from the drop-down menu of the new file button on the toolbar, EditPad gives that file the default line break style of the chosen file type.
Note that EditPad never silently converts existing line breaks to a different style when you open a file. If you set the default line break style for Perl scripts to UNIX, and then open a Perl script using Windows line breaks, then EditPad saves that script with Windows line breaks unless you use Convert|Line Break Style|To UNIX.
If you need to deal with different line break styles, you should turn on the line break style status bar indicator. It indicates the line break style being used by the current file and whether it uses that style exclusively or mixed with other styles.
EditPad Pro can edit binary files in hexadecimal mode. If you know that files of a certain type don’t contain (much) human-readable content, select “always open files of this type in hexadecimal mode”. If you know files of a certain type to be text files, select “never open files of this type in hexadecimal mode” to prevent stray NULL characters from making EditPad think the file is binary.
If you’re not sure, select “open files detected as being binary in hexadecimal mode”. Then EditPad Pro will check if the file contains any NULL characters. Text files should not contain NULL characters, though improperly created text files might. Binary files frequently contain NULL characters.
Making the wrong choice here causes no harm. You can instantly switch between text and hexadecimal mode by picking View|Hexadecimal in the menu. Unlike many other editors, EditPad Pro will preserve the exact contents of binary files even when you view them in text mode. Even files with NULL characters will be properly displayed in text mode. (Many applications truncate text files at the first NULL, since that character is often used as an end-of-data signal.)
The “record size” is the number of bytes that EditPad Pro displays on each line in hexadecimal mode. If you enter zero, you get EditPad Pro’s default behavior of showing the smallest multiple of 8 bytes that fits within the width of EditPad’s window. If you enter a positive number, that’s the number of bytes EditPad Pro displays on a line. You can enter any number. It doesn’t have to be divisible by 8 or by 2.
Set “hex editor sections” to “hexadecimal and ASCII” to get the typical hex editor view with the hexadecimal representation of the bytes in the center of the editor, and the ASCII representation of the bytes in the right-hand column. Choose “hexadecimal only” or “ASCII only” to see only either representation. Select “split hexadecimal and ASCII” if you want one view to display the hexadecimal representation and the other view the ASCII representation after using View|Split Editor. If the editor is not split, there is no difference between the “split hexadecimal and ASCII” and “hexadecimal and ASCII” choices.